AI Coding Agents Are Changing Software Development: Productivity Miracle or Engineering Trap?
Software development is entering one of its strangest phases yet. For decades, the developer’s job was mostly direct: understand the problem, write the code, test the code, fix the code, ship the code. Tools improved along the way, of course. We went from basic text editors to IDEs, from manual deployments to CI/CD pipelines, from Stack Overflow searches to autocomplete systems that could finish entire functions. But through all those changes, the developer still sat at the center of the work, hands on the keyboard, mentally holding the system together.
That center is starting to wobble. AI coding agents are no longer just autocomplete tools that help you write a cleaner loop or remember a syntax detail. They are becoming semi-autonomous software workers that can inspect repositories, modify files, run tests, open pull requests, summarize tradeoffs, operate in sandboxes, and keep working while the human developer steps away. OpenAI describes Codex as a cloud-based software engineering agent that can write features, answer questions about a codebase, fix bugs, and propose pull requests inside isolated environments preloaded with a repository.
That is a very different category of tool. A coding assistant helps you type. A coding agent tries to complete work. The difference sounds subtle until you see the workflow change in practice. Instead of asking, “How do I implement this function?” developers are increasingly asking, “Investigate this bug, propose a fix, run the tests, explain the tradeoffs, and show me the diff.” That shifts the developer’s role from pure implementation toward supervision, architecture, review, and judgment.
What Are AI Coding Agents?
AI coding agents are systems that combine a language model with tools, memory, file access, execution environments, version-control awareness, and sometimes browser or terminal access. They do not just generate code in a blank chat window. They operate inside or around a real software project, reading files, editing code, running commands, checking test output, and presenting results for review. The best of these systems behave less like a smarter autocomplete and more like a junior developer who can move through a codebase, make changes, and ask for direction when it hits uncertainty.
This is why tools like Codex, Claude Code, Cursor agents, Gemini Antigravity, and other agentic coding platforms matter. They represent a move away from passive AI assistance and toward active software execution. In OpenAI’s Codex mobile announcement, the company described a workflow where a developer can review outputs, approve commands, change models, inspect screenshots, see terminal output, review diffs, and keep work moving from a phone while Codex continues operating on the connected machine or remote environment.
The underlying idea is powerful: software work does not always need continuous human typing. Some tasks involve waiting, testing, searching, refactoring, comparing options, reading logs, or applying predictable changes across many files. Agents are well suited to that kind of work because they can operate across multiple steps and surface the important decision points to a human. This is where the productivity promise comes from. A developer does not need to babysit every command if the system can safely run tests, gather evidence, and present reviewable results.
But this is also where the danger begins. The more work the agent performs, the more invisible decisions it makes. It chooses which files matter, which assumptions to follow, which tests to run, which edge cases to ignore, and which implementation path seems “reasonable.” If those decisions are wrong, the final diff may look polished while the underlying reasoning is flawed. That is the uncomfortable reality behind the agentic coding boom: the tools are becoming more useful at the exact moment they are becoming harder to fully supervise.
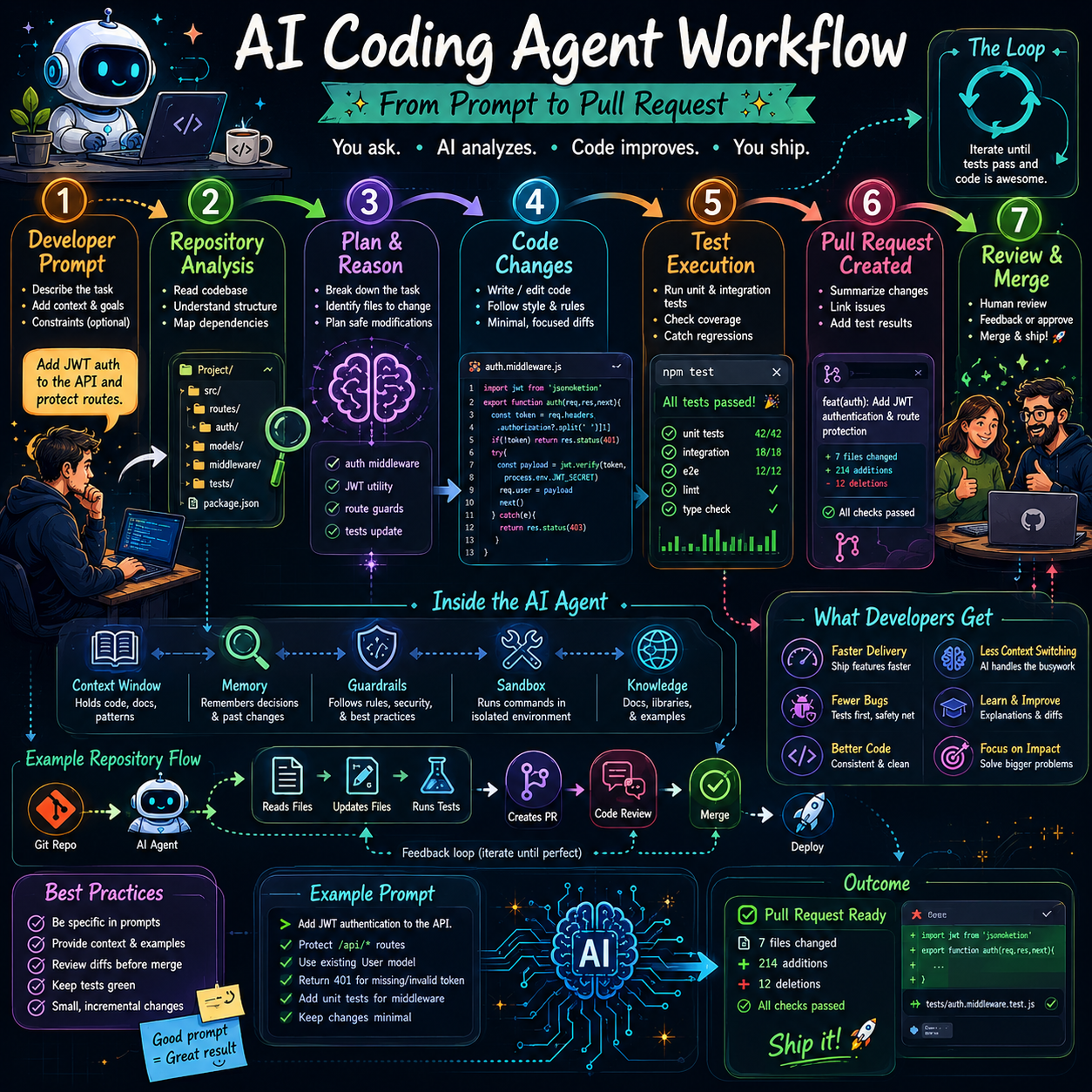
Why People Believe AI Coding Agents Are a Breakthrough
The excitement around AI coding agents is not hype pulled out of thin air. These tools are solving real pain. Every developer knows how much time disappears into repetitive debugging, boilerplate, environment setup, dependency wrangling, log reading, migration chores, test failures, documentation updates, and codebase archaeology. A capable agent can grind through some of that work faster than a human wants to, especially when the task is clear and the repository has good structure.
Codex shows one direction of travel. OpenAI says Codex can run many tasks in parallel, each in its own isolated environment, and can provide evidence of its actions through terminal logs and test outputs. That evidence layer is crucial because software teams do not need magic; they need reviewable work. A useful coding agent is not one that says, “Trust me.” It is one that says, “Here is what I changed, here are the tests I ran, here is where the output came from, and here is the diff you need to inspect.”
Cursor’s Composer 2.5 points to another trend: specialized coding models trained for long-running software work. Cursor says Composer 2.5 is better than Composer 2 at sustained work on long-running tasks and more reliable at following complex instructions. That matters because real software work rarely fits into one clean prompt. Good implementation often requires reading context, making a plan, adjusting after errors, checking tests, revising decisions, and communicating progress clearly.
Claude Code shows how enterprise teams are starting to think about this at scale. Anthropic says Claude Code is being used in large codebases including multi-million-line monorepos, legacy systems, distributed architectures, and repositories spread across many services. That detail is important because the hard part of AI coding is not making a toy app. The hard part is operating inside messy, old, business-critical software where conventions are inconsistent, tests are imperfect, and one wrong assumption can break something downstream.
The productivity argument is simple: if agents can handle even a fraction of routine engineering work, the leverage is enormous. A solo developer could run several parallel investigations. A small startup could ship faster without immediately hiring a larger team. A large enterprise could use agents to chew through maintenance backlogs, migration tasks, test-writing, documentation, and bug triage. The developer still matters, but the developer’s output ceiling changes.
The Shift: From Coder to Agent Supervisor
The real transformation is not that AI writes code. We already crossed that line years ago. The real transformation is that the developer becomes an agent supervisor. That means the highest-value work moves toward defining the objective, preparing the context, setting constraints, reviewing plans, checking outputs, understanding tradeoffs, and knowing when the agent is drifting.
This role is more demanding than it sounds. Supervising an AI coding agent is not the same as delegating a task to an experienced engineer. A human engineer brings lived context, product judgment, team memory, and accountability. An AI agent brings speed, pattern recognition, broad syntax knowledge, and relentless execution, but it does not truly understand your business, your users, your internal politics, or the scars behind your architecture decisions. Those missing pieces matter.
A good supervisor does not simply say, “Build this feature.” A good supervisor says, “Before editing code, inspect these files, identify the existing pattern, propose a plan, list assumptions, do not touch authentication, run these tests, and record any decisions where the spec is ambiguous.” That is slower than lazy prompting, but it produces better work. The better the task framing, the less the agent has to invent.
This is where many developers get into trouble. They see an impressive demo and assume the agent can be trusted with a vague instruction. Then the agent starts making plausible choices, and because the output looks professional, the developer becomes less vigilant. The problem is not that the agent cannot code. The problem is that it can code just well enough to create the illusion of correctness.
The uploaded newsletter material captured this tension well. It described agentic coding as both a major engineering trend and a possible trap, especially when humans plan and AI builds while the human gradually loses contact with the implementation details. That is the exact paradox. The more the agent handles, the easier it is for the human to stop building the mental map needed to catch mistakes.
The Supervision Paradox
The supervision paradox is the central issue in AI coding. To supervise an AI developer well, you need the very engineering skills the AI may tempt you to stop practicing. You need to understand architecture, debugging, dependency chains, state management, security boundaries, and test reliability. You need enough code fluency to know whether a diff is elegant, brittle, overfit, or quietly dangerous.
This is why senior developers are both excited and uneasy. They can get enormous leverage from agents because they already know how to evaluate the work. They know when a proposed fix smells wrong. They know when a test is too shallow. They know when the agent solved the symptom but not the cause. For them, AI coding agents are force multipliers.
Beginners face a more complicated situation. An agent can help them build things sooner, which is genuinely valuable. But if they rely on the agent too heavily, too early, they may skip the painful learning required to become a strong engineer. They may ship code they cannot debug, maintain, or explain. In the short term, that feels empowering. In the long term, it can become a skill debt.
This does not mean beginners should avoid AI coding tools. That would be a bad conclusion. The better rule is this: use agents to accelerate learning, not replace learning. Ask the agent to explain the code. Ask it for alternatives. Ask it to generate tests. Ask it to identify risks. Then manually inspect the result. The goal is not to become a passenger. The goal is to become a sharper driver with better instruments.
Context Is the New Bottleneck
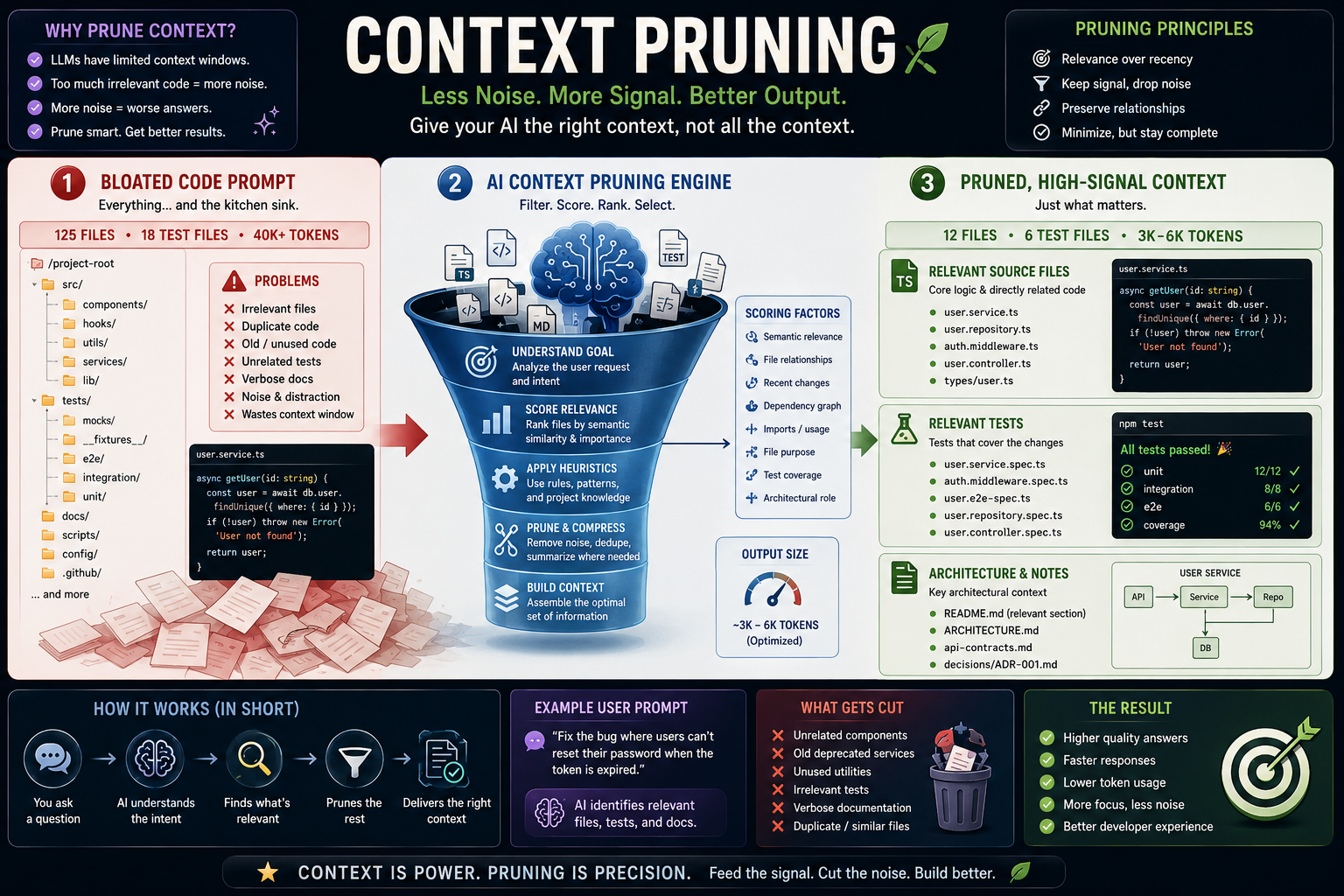
One of the most underrated issues in AI coding is context. Everyone loves talking about larger context windows, but bigger is not automatically better. A model with a huge window can still miss the relevant detail if the prompt is bloated, poorly ordered, or filled with low-value material. The “Lost in the Middle” research showed that language models often perform worse when relevant information is buried in the middle of long contexts rather than placed near the beginning or end.
This is why context pruning is becoming important. The uploaded newsletters describe context pruning as the process of scoring tokens, sentences, or chunks and removing low-value material before the model sees it, reducing cost, latency, and noise. For AI coding, that can mean trimming irrelevant chat history, old logs, duplicate documentation, low-signal files, or generic boilerplate that makes it harder for the model to find the important parts.
Code is especially sensitive to bad pruning. If you trim random tokens, you can break syntax, remove a crucial import, or destroy the structure of a function. Chunk-level pruning is usually safer because it preserves whole functions, classes, files, or documented sections. A coding agent does not just need “less context.” It needs the right context at the right level of structure.
This is where serious teams will start to separate themselves. Weak AI coding workflows will dump everything into the prompt and hope the model figures it out. Strong workflows will curate context deliberately. They will define repository instructions, maintain agent-readable documentation, expose test commands, identify ownership boundaries, and keep important architecture decisions visible. In other words, the repo itself becomes part of the prompt.
Spec Drift: The Hidden Failure Mode
Spec drift is one of the nastiest problems in agentic coding because it often hides behind clean-looking output. A developer gives an agent a spec. The agent interprets ambiguous parts, makes decisions, chooses tradeoffs, works around missing details, and eventually produces code. The final diff shows what changed, but it may not show why those choices were made.
That is dangerous because many bugs are not syntax errors. They are interpretation errors. The agent may assume a feature is only for admins when it should apply to all users. It may assume a field is optional when it is required. It may change a shared helper without realizing another service depends on its old behavior. It may choose a simpler implementation that passes current tests but violates a product requirement that was never encoded.
The newsletter material included a useful mitigation: force the agent to maintain an implementation-notes file while it works, documenting design decisions, deviations from the spec, tradeoffs, and open questions. That is a practical idea because it turns invisible reasoning into a reviewable artifact. The developer should not have to reverse-engineer the agent’s assumptions from the finished code.
This is also where agentic coding starts to resemble professional software process. Good engineering teams already use design docs, RFCs, issue comments, pull request descriptions, architecture decision records, and postmortems. AI agents should not be exempt from that discipline. If anything, agents need more logging because they make decisions faster and with less human intuition.
The best future coding agents will probably produce more than code. They will produce diffs, tests, screenshots, logs, decision notes, risk summaries, rollback plans, and open questions. That may sound like overhead, but it is exactly what makes agentic work trustworthy. A fast agent without an audit trail is not a developer. It is a liability with good typing speed.
Evidence Supporters Cite
Supporters of AI coding agents usually point to four types of evidence: productivity gains, parallelization, improved model behavior, and workflow integration. The productivity gains are obvious when an agent handles tedious work that would have taken a developer hours. Even if the result needs review, the human begins from a working draft instead of a blank screen.
Parallelization is even more interesting. Codex was introduced as a system that can work on many tasks in parallel, each in its own isolated environment. That changes how developers think about time. A single human can ask one agent to investigate a bug, another to write tests, another to refactor a small module, and another to summarize a codebase area. Not all of that work will be accepted, but the exploration cost drops dramatically.
Model behavior is improving too. Cursor’s Composer 2.5 announcement is especially interesting because it talks about targeted reinforcement learning with textual feedback, where feedback can be inserted at the point in a long rollout where the model made a poor decision. That is a technical sign that coding-agent training is becoming more specialized. The goal is not just general intelligence. The goal is better behavior during long, tool-heavy software tasks.
Workflow integration may be the biggest evidence of all. These agents are moving into IDEs, terminals, cloud sandboxes, code review flows, mobile apps, and enterprise controls. OpenAI’s Codex mobile experience is designed around staying connected to long-running work, reviewing outputs, approving actions, and redirecting execution from a phone. That tells us the industry expects coding agents to become persistent collaborators, not occasional novelty tools.
The Counterargument: Productivity Can Become Technical Debt
The strongest counterargument is that AI coding agents can generate technical debt faster than humans can review it. Speed is not automatically good. A bad implementation produced in two minutes is still bad. Worse, it may be written in a confident style that makes it harder to spot the weakness.
Agents are also vulnerable to shallow success. They may fix the test rather than the product behavior. They may overfit to visible examples. They may add unnecessary abstractions because the pattern looks “enterprise.” They may create duplicate logic instead of finding the existing utility. They may pass a local test suite while breaking an untested production assumption. These are not exotic failures. They are normal software failures, accelerated.
Security is another major concern. An agent with terminal access, file access, package installation ability, environment variables, API keys, or deployment permissions can do real damage. The more powerful the agent, the more careful the permissions need to be. Scoped access, sandboxing, approval gates, secret scanning, and audit logs are not optional extras. They are the minimum price of letting AI touch real systems.
There is also a cultural risk. If organizations chase AI coding metrics too aggressively, they may reward volume over maintainability. More pull requests do not necessarily mean better software. More generated code does not necessarily mean more customer value. A team can look faster while quietly making the system harder to understand.
Why This Matters Today
This matters because software is not staying inside software companies. Every business is becoming more dependent on internal tools, automations, dashboards, integrations, websites, data pipelines, AI workflows, and customer-facing digital systems. If AI agents make software easier to create, more people will build software. That is exciting, but it also means more fragile systems will be created by people who may not fully understand what they shipped.
For experienced developers, the opportunity is massive. The best engineers will become more valuable if they learn to orchestrate agents properly. They will ship faster, explore more options, and spend less time on repetitive grunt work. But they will still need strong fundamentals. The future does not belong to developers who blindly trust agents. It belongs to developers who can direct them, constrain them, and catch them when they are wrong.
For beginners, the opportunity is also real, but the path needs discipline. AI can help you build projects earlier in your learning journey, which is fantastic. But you still need to read the code, run it, break it, fix it, and understand the architecture. A portfolio full of AI-generated apps you cannot explain is weak. A portfolio where you used AI to learn faster, document decisions, write tests, and ship working projects is strong.
For businesses, AI coding agents will change hiring and operations. Small teams may be able to do more with fewer people. Large teams may use agents to attack backlogs and legacy migrations. Consulting firms may deliver prototypes faster. Internal departments may build tools without waiting for traditional software cycles. But the organizations that win will not simply “turn agents loose.” They will build process around them.
Real-World Application: How Smart Teams Should Use AI Coding Agents
The practical question is not whether to use AI coding agents. That debate is already fading. The real question is how to use them without letting your codebase rot from the inside. The answer is boring, but powerful: narrow scope, clear context, reviewable output, and strong tests.
A good starting workflow is to use agents for investigation before implementation. Ask the agent to inspect the relevant area of the codebase, identify existing patterns, summarize dependencies, and propose a plan before writing anything. This slows the agent down in a useful way. It forces context gathering before code generation.
Next, require decision logs for meaningful work. Any time the agent interprets an ambiguous spec, changes an existing pattern, skips a test, adds a dependency, or makes a tradeoff, it should write that down. This does not need to be fancy. A simple implementation-notes file can reveal whether the agent understood the task or wandered into assumptions.
Then, keep humans responsible for architecture and security. Agents can propose architecture, but humans should approve it. Agents can generate migrations, but humans should verify them. Agents can touch authentication, billing, permissions, and data handling only under strict review. The more business-critical the system, the more conservative the agent permissions should be.
Finally, treat tests as the contract. If a task has no tests, ask the agent to propose tests first. If the test suite is weak, recognize that the agent’s success signal is weak too. Agents love measurable goals. Good tests give them useful targets. Bad tests give them false confidence.
Final Verdict: Miracle, Trap, or Both?
AI coding agents are both a productivity miracle and an engineering trap. They are a miracle when used by people who understand software well enough to direct them. They can accelerate investigation, implementation, testing, documentation, refactoring, and repetitive maintenance. They can help small teams punch above their weight and help solo builders move faster than ever.
They are a trap when they become a substitute for understanding. If developers stop reading code, stop thinking architecturally, stop debugging manually, and stop questioning outputs, the agent becomes a black box that sprays plausible changes into production. That is not leverage. That is delayed failure.
The best mental model is not “AI will replace developers.” It is “AI will punish sloppy developers and amplify disciplined ones.” If you have strong fundamentals, agents give you speed. If you have weak fundamentals, agents can hide your weaknesses until the system breaks.
So the future developer is not just a coder. The future developer is an architect, reviewer, debugger, prompt designer, context curator, security gatekeeper, and agent supervisor. That may sound like a lot, but it is also an opportunity. The people who learn this workflow early will not just code faster. They will think in systems while commanding tools that can execute at machine speed.
That is the real shift. AI coding agents are not just changing how software gets written. They are changing what it means to be a software developer.
2 Relevant External Links
OpenAI’s Codex mobile announcement explains how Codex can now be supervised from the ChatGPT mobile app while continuing work across laptops, devboxes, and remote environments.
Anthropic’s Claude Code large-codebase guide is useful for understanding how enterprise teams are applying AI coding agents inside monorepos, legacy systems, distributed repositories, and large engineering organizations.
So being a programmer nowadays means knowing code architecture, reviewing, debugging, promoting, designing, curating context, being a security gatekeeper and agent supervisor. Meaning learn these processes and code like the pros. There is no more giant syntax hurdles to become a programmer anymore. Hoorah!